
Nebula Graph 服务端是什么版本?
这是返回的数据类型为UNKOWN
服务端版本是1.1.0 
我debug了一下,在NebulaVertexIterator这里报Method threw ‘java.lang.IllegalArgumentException’ exception. Cannot evaluate com.vesoft.nebula.tools.connector.reader.NebulaEdgeIterator.toString()
你把断点打在 NebulaVertexIterator中调用process()的这一行,
if (next != null) {
val processResult: Result[Row] = new ScanVertexProcessor(metaClient)
.process(nebulaOptions.spaceName, next)
.asInstanceOf[Result[Row]]
然后看下红框内的代码,你报出的错误信息是RowReader中做数据类型转换时无法识别类型而报出的,看下schema中每一个column对应的数据类型是什么。
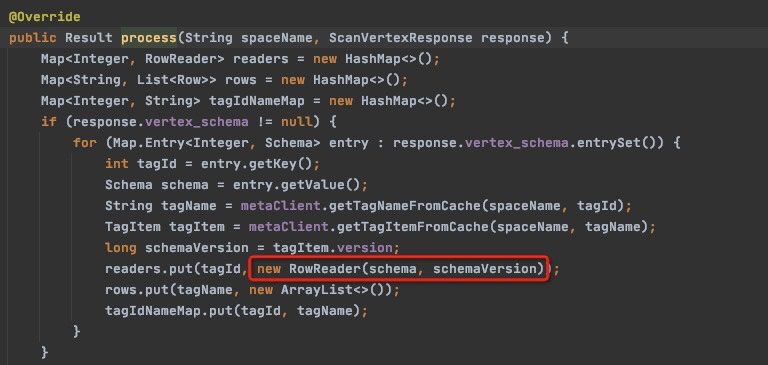
有个schema_prop的没有类型,其他的column都有type
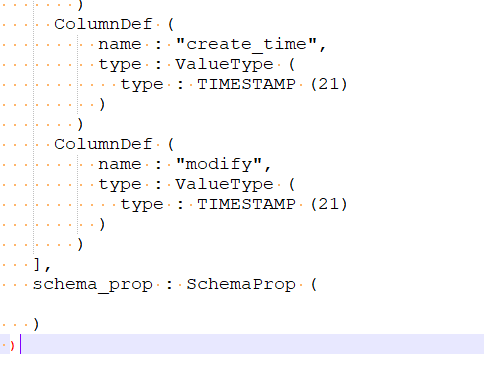
mark
是1.0的客户端未对TIMESTAMP类型提供支持,我们修一下
好的谢谢,修复好麻烦会回复一下 
更新了java-client, 你拉一下新代码,重新编译打包一下spark-conenctor @SZU-IC
git clone -b v1.0 https://github.com/vesoft-inc/nebula-java.git
好的谢谢啦 ,我去试试


最新的java-client 1.1.0版本中加上了TIMESTAMP,spark-connector的pom中使用的java-client版本也更新为1.1.0。
你看下你下载的spark-connector pom中使用的java-client版本呢
我这边spark-connector中pom.xml的client已改成1.1.0,但还是报错 
你看java-client1.1.0代码中 也没有case TIMESTAMP么

client-1.1.0中有case TIMESTAMP的,你确认下spark-connector中pom里面的nebula.version版本是不是1.1.0.
<properties>
<spark.version>2.4.4</spark.version>
<nebula.version>1.1.0</nebula.version>
<compiler.source.version>1.8</compiler.source.version>
<compiler.target.version>1.8</compiler.target.version>
</properties>我这边的版本也是1.1.0

我的代码是克隆下来的,68行有case TIMESTAMP,但113行没有case TIMESTAMP,是不是这里出问题了?
对,这里decode的时候应该有timestamp的。
那你们需不需要再fix一下 