- nebula 版本:v2.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):Docker
- 硬件信息
- 磁盘( 必须为 SSD ,不支持 HDD)SSD
- CPU、内存信息:40C 126G
- 出问题的 Space 的创建方式:执行
describe space xxx;
- 问题的具体描述
数据的tag和index如下:
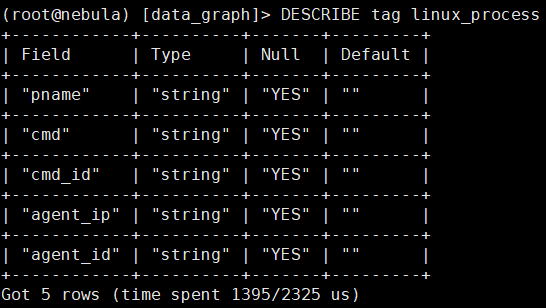
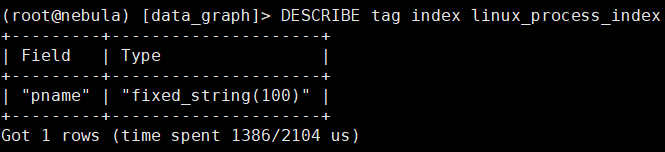
我重复不间断的入库tag为linux_process点数据,每个入库的点的vid都是不同的,现在有如下现象:
请问在带索引入库时,有没有可以让入库速率稳定在高点的最佳实践呢?
看了 https://discuss.nebula-graph.com.cn/t/topic/849这个贴里,里面最后wumin提到了"block cache 够大的话(放的下索引),batch insert写入是原来的80%。block cache不够放下的话,你可以放弃这个思路了"
这个block cache可以加快带索引的入库速率吗?
建议在最初入库的时候先不要创建索引,数据导入完成后,再 create index,rebuild index。这样会快些。
我们查询的频率也比较高,如果每次都create index,rebuild index,drop index的话,对查询的影响太大了。
而且我们插入也是24小时不间断的,这样在加索引查询时势必会造成入库速率的抖动,可能会导致上游数据的积压。
为什么要每次都create | rebuild | drop index? 业务场景可以描述一下吗?比如初始入库的数据量,不间断插入的频率,数据量,峰值等。
这里需要了解上文中提到的“入库”,指的是初始数据导入?还是在数据库服务过程中的持续 insert?
一般性能衰减会出现在初始数据导入的阶段,所以建议最初导入数据的时候不带索引。导入完成后再create | rebuild index。
我们的业务是持续不间断的24小时insert导入数据,如果为了查询建立的索引不drop掉的话,后续入库的数据会自动建立索引,导致入库变慢。
我们是接收上游kafka的数据,转化后导入nebula,目前是需要从kafka按5万/s的数据量来消费才不会造成数据积压。
我们的业务场景的数据量是比较稳定的,波峰和波谷没有那么明显。
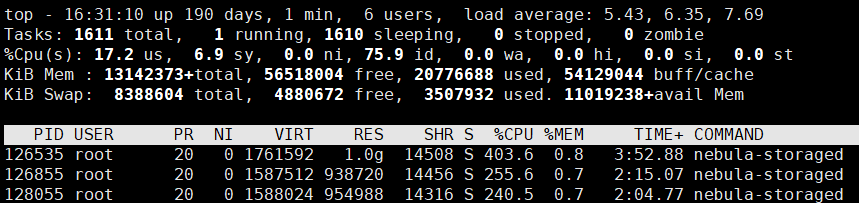
你好,我用的docker部署,storage配置一个节点时,带索引入库的storage的cpu使用率是1000%左右,如下图:
配置三个节点时(三个节点在一台机器上),这三个节点的cpu使用率总和也是1000%左右,而且入库速率也没有变快,磁盘写入速度远没有达到瓶颈
想问下增加storage节点为什么没有起到增大吞吐的作用呢?
docker compose配置里用的是docker默认的网络方案overlay,性能瓶颈会比较大。
如果应用在生产环境,建议部署在真实的三台物理服务器上,通过10G/25G网络组建集群。
再请教下,如果用spark exchange直接底层sst导入的话,带索引的情况是需要定时rebuild索引吗
创建过索引之后,插入的点是带索引的,就不用rebuild了