你好,再问下你是怎么清除的本地maven库呢,我用mvn clean -U & mvn dependency:purge-local-repository这两个命令做了清理,还把/home/consumer/.m2/repository/com/vesoft这个目录的clinet都rm了,exchange也是这样操作一遍,然后重新编译,还是报了上边那个“Value: 23399562’s type is unexpected”的错误。
- 这个NPE的问题在你清除mvn库之后还存不存在?
- 下面这个是因为你的配置中把 json文件的同一个字段同时作为了vid和属性srcId,而vid和srcId的数据类型不同所造成的。这个 问题已经在 support data's field both as VID and property with different dataType by Nicole00 · Pull Request #19 · vesoft-inc/nebula-spark-utils · GitHub PR中处理了,上周五才合进去。
1、这个NPE问题还是有:
21/01/25 10:31:20 WARN scheduler.TaskSetManager: Lost task 29.0 in stage 2.0 (TID 7, 192.168.100.72, executor 0): java.lang.NullPointerException
at com.vesoft.nebula.client.meta.MetaManager.fillMetaInfo(MetaManager.java:93)
at com.vesoft.nebula.client.meta.MetaManager.getSpace(MetaManager.java:162)
at com.vesoft.nebula.encoder.NebulaCodecImpl.getSpaceVidLen(NebulaCodecImpl.java:54)
at com.vesoft.nebula.encoder.NebulaCodecImpl.vertexKey(NebulaCodecImpl.java:75)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$1$$anonfun$apply$1.apply(VerticesProcessor.scala:142)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$1$$anonfun$apply$1.apply(VerticesProcessor.scala:118)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.sort_addToSorter_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$2.apply(VerticesProcessor.scala:161)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$2.apply(VerticesProcessor.scala:154)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2、我在编译exchange的已经git pull了,可以看到确实已经包含了上周五的代码,但是还是报上面的错误
(base) [consumer@localhost nebula-exchange]$ git log
commit f00e94c5389eeff68529ce19027f659216c65c15
Merge: 413bfef 87ebcc5
Author: jude-zhu <51590253+jude-zhu@users.noreply.github.com>
Date: Fri Jan 22 16:32:05 2021 +0800
Merge pull request #19 from Nicole00/rc1
support data's field both as VID and property with different dataType
commit 87ebcc58588d9e83d014379cffded727bfd507a8
Author: Nicole00 <16240361+Nicole00@users.noreply.github.com>
Date: Fri Jan 22 16:25:27 2021 +0800
revert remote path
commit 85d726545d6e00c609794075f84323391aae072f
Author: Nicole00 <16240361+Nicole00@users.noreply.github.com>
Date: Fri Jan 15 16:36:07 2021 +0800
support data both as VID and property with different dataType
我使用跟你一模一样的nebula tag和edge, 重新拉取github代码编译后 走了一遍你的流程,可以生成对应的sst文件
我感觉你使用的还是旧的包呢,检查下你使用的jar包是不是最新打成的
刚看了一下,都是最新生成的。
那我也把maven库、java-client和exchange的源码都删了,重新编译一下试试
我完全重新编译exchange,然后把json数据中的数字都用字母字符串替代,可以生成sst了,但是还有有一些报错,这些报错影响大吗
21/01/25 15:14:55 WARN scheduler.TaskSetManager: Lost task 10.0 in stage 9.0 (TID 112, 192.168.100.72, executor 0): java.io.IOException: Failed on local exception: java.io.IOException; Host Details : local host is: "localhost/127.0.0.1"; destination host is: "localhost":9000;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:776)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy20.complete(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.complete(ClientNamenodeProtocolTranslatorPB.java:462)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy21.complete(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:2291)
at org.apache.hadoop.hdfs.DFSOutputStream.closeImpl(DFSOutputStream.java:2267)
at org.apache.hadoop.hdfs.DFSOutputStream.close(DFSOutputStream.java:2232)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
at com.vesoft.nebula.exchange.ErrorHandler$.save(ErrorHandler.scala:24)
at com.vesoft.nebula.exchange.processor.ReloadProcessor.com$vesoft$nebula$exchange$processor$ReloadProcessor$$processEachPartition(ReloadProcessor.scala:47)
at com.vesoft.nebula.exchange.processor.ReloadProcessor$$anonfun$process$1.apply(ReloadProcessor.scala:24)
at com.vesoft.nebula.exchange.processor.ReloadProcessor$$anonfun$process$1.apply(ReloadProcessor.scala:24)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException
at org.apache.hadoop.ipc.Client$Connection.waitForWork(Client.java:946)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:978)
Caused by: java.lang.InterruptedException
... 2 more
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Starting task 10.1 in stage 9.0 (TID 114, 192.168.100.72, executor 0, partition 10, PROCESS_LOCAL, 8334 bytes)
21/01/25 15:14:55 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 9.0 (TID 102, 192.168.100.72, executor 0): org.apache.spark.util.TaskCompletionListenerException: Filesystem closed
Previous exception in task: Filesystem closed
org.apache.hadoop.hdfs.DFSClient.checkOpen(DFSClient.java:808)
org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:868)
org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:934)
java.io.DataInputStream.read(DataInputStream.java:149)
org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216)
org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:186)
org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
org.apache.spark.sql.execution.datasources.HadoopFileLinesReader.hasNext(HadoopFileLinesReader.scala:69)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:101)
org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
scala.collection.Iterator$class.foreach(Iterator.scala:891)
scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
com.vesoft.nebula.exchange.processor.ReloadProcessor.com$vesoft$nebula$exchange$processor$ReloadProcessor$$processEachPartition(ReloadProcessor.scala:36)
com.vesoft.nebula.exchange.processor.ReloadProcessor$$anonfun$process$1.apply(ReloadProcessor.scala:24)
com.vesoft.nebula.exchange.processor.ReloadProcessor$$anonfun$process$1.apply(ReloadProcessor.scala:24)
org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
org.apache.spark.scheduler.Task.run(Task.scala:123)
org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
java.lang.Thread.run(Thread.java:748)
at org.apache.spark.TaskContextImpl.invokeListeners(TaskContextImpl.scala:138)
at org.apache.spark.TaskContextImpl.markTaskCompleted(TaskContextImpl.scala:116)
at org.apache.spark.scheduler.Task.run(Task.scala:133)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Lost task 7.0 in stage 9.0 (TID 109) on 192.168.100.72, executor 0: java.io.IOException (Failed on local exception: java.io.IOException; Host Details : local host is: "localhost/127.0.0.1"; destination host is: "localhost":9000; ) [duplicate 1]
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Starting task 7.1 in stage 9.0 (TID 115, 192.168.100.72, executor 0, partition 7, PROCESS_LOCAL, 8334 bytes)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Starting task 0.1 in stage 9.0 (TID 116, 192.168.100.72, executor 0, partition 0, PROCESS_LOCAL, 8332 bytes)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 9.0 (TID 110) in 352 ms on 192.168.100.72 (executor 0) (1/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 11.0 in stage 9.0 (TID 113) in 352 ms on 192.168.100.72 (executor 0) (2/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 9.0 (TID 107) in 380 ms on 192.168.100.72 (executor 0) (3/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 9.0 (TID 103) in 382 ms on 192.168.100.72 (executor 0) (4/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 9.0 (TID 111) in 381 ms on 192.168.100.72 (executor 0) (5/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 9.0 (TID 106) in 382 ms on 192.168.100.72 (executor 0) (6/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 9.0 (TID 105) in 383 ms on 192.168.100.72 (executor 0) (7/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 9.0 (TID 108) in 383 ms on 192.168.100.72 (executor 0) (8/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 9.0 (TID 104) in 384 ms on 192.168.100.72 (executor 0) (9/12)
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Lost task 0.1 in stage 9.0 (TID 116) on 192.168.100.72, executor 0: org.apache.spark.util.TaskCompletionListenerException (Filesystem closed
Previous exception in task: Filesystem closed
org.apache.hadoop.hdfs.DFSClient.checkOpen(DFSClient.java:808)
org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:868)
org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:934)
java.io.DataInputStream.read(DataInputStream.java:149)
org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216)
org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:186)
org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
org.apache.spark.sql.execution.datasources.HadoopFileLinesReader.hasNext(HadoopFileLinesReader.scala:69)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:101)
org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
scala.collection.Iterator$class.foreach(Iterator.scala:891)
scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
com.vesoft.nebula.exchange.processor.ReloadProcessor.com$vesoft$nebula$exchange$processor$ReloadProcessor$$processEachPartition(ReloadProcessor.scala:36)
com.vesoft.nebula.exchange.processor.ReloadProcessor$$anonfun$process$1.apply(ReloadProcessor.scala:24)
com.vesoft.nebula.exchange.processor.ReloadProcessor$$anonfun$process$1.apply(ReloadProcessor.scala:24)
org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:980)
org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
org.apache.spark.scheduler.Task.run(Task.scala:123)
org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
java.lang.Thread.run(Thread.java:748)) [duplicate 1]
21/01/25 15:14:55 INFO scheduler.TaskSetManager: Starting task 0.2 in stage 9.0 (TID 117, 192.168.100.72, executor 0, partition 0, PROCESS_LOCAL, 8332 bytes)
- 下面的问题可以参考帖子 使用exchange并发 spark-submit --master "local[16]" 报错 的解决方法,这类问题在Hadoop的社区有一些解决方式可借鉴,具体解决步骤可以去google下,我就不搬运了哈~
-
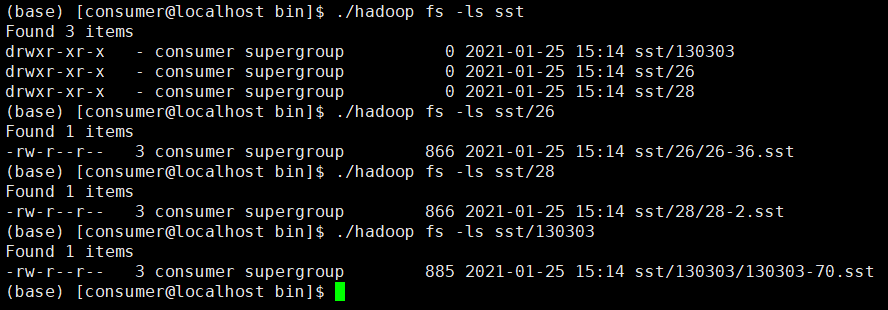
2.0的exchange生成的sst文件的规则是:
位于hdfs上,且路径为/namespace/partition_number/{part}-{task}.sst
ps: 查看1.0的exchange代码会发现,1.0的exchange生成的sst文件的实际命名不是{TYPE}-${FIRST_KEY_IN_THIS_FILE}, 应该是文档未更新。 -
当前版本的 SST导入未正式发布,exchange生成的SST文件还不能应用到后续的download和ingest功能。
1、我按照这个帖子重新配置了hadoop,现在没有报错且可以成功生成sst了;
2、这个路径里的namespace是nebula里的space id吗,还有我上面贴的图里,有一个名为130303的目录,这个不是partition-number,我的partition设置的32,这个不知道是个啥?
3、现在nebula 2.0的sst导入功能还不可用吗,这个大概什么时候可以开发完呢,我们目前正在2.0上测试sst导入的功能,后续在生产环境应用也是打算使用nebula 2.0;
边的key编码之后计算出的partition是错误的,这个我们后面会修复下partition的计算。
sst导入功能 正常使用预计在ga之后了, 建议你们生产环境下使用ga版本~
1 个赞
ga版本指的是nebula 1.0吗
Nebula 1.0 GA 发布过了,Nicole 说的应该是 2.0 GA
1 个赞
但是2.0 GA目前用不了sst导入功能,我们目前要带索引入库,但是用NGQL方式有性能问题,所以想使用sst导入的方式来替代。
2.0GA还没有发布呢,exchange的sst导入预计要和2.0的GA一起放出了
奥奥,请问2.0 GA有大概发布的时间点么
暂时还没定,我们有了进一步的消息第一时间和你说哈
请问这个part不对的问题,修复了吗?