不能match(n:student) return n,也不建议随意建索引,那么如何快速查看导入了哪些数据呢
我按照文档尝试导入了student的数据数据,导入结果如下
[nebula@hadoop-node-2 mytest]$ ./nimporter --config ./nimportercfg/20210428-nebula-importer-cfg.yml
2021/04/29 10:39:06 --- START OF NEBULA IMPORTER ---
2021/04/29 10:39:06 Please configure file schema: files[0].schema
2021/04/29 10:39:07 --- END OF NEBULA IMPORTER ---
但是我该怎么查询导入的数据呢?
我又去看这个这个文章
https://docs.nebula-graph.com.cn/2.0/3.ngql-guide/7.general-query-statements/2.match/
里面讲的不要随意建立索引,但是看了几遍之后我觉得,不建索引就不能用match,真相是这样吗?
导入数据后,在没有作其他操作的前体现,我想看到我导入的数据改怎么做呢?
这里想表达的是,做批量倒入数据的时候,建议先不要建索引,因为这样会影响写入性能,写入性能下降比较明显。所以是希望用户需要用到索引的时候,在导入完数据之后,通过 rebuild index 进行索引的创建,这样效率更高。
导入数据后,在没有作其他操作的前体现,我想看到我导入的数据改怎么做呢? 按我现在的需求就很简单,导入了example/student的数据,我想看一下导入的数据该怎么查询呢
数据路径./nebula-importer/examples/v2/student.csv
你可以看下 stats的功能
https://docs.nebula-graph.com.cn/2.0/3.ngql-guide/18.operation-and-maintenance-statements/4.job-statements/#submit_job_stats
https://docs.nebula-graph.com.cn/2.0/3.ngql-guide/7.general-query-statements/6.show/14.show-stats/
!
这两个都不是我想要的,这样也看不出我导入的数据的内容是否和csv的一致。请问有没有办法看到我导入的数据呢,导入数据后,在没有作其他操作的前体现,我想看到我导入的数据改怎么做呢?
比如 select * from tb_name ,就是这样一个简单的需求。

如果我不需要建立索引该怎么查询呢,或者说没有索引 nebula就不能查询了吗。如果是这样请在文档里补充说明一下,为了验证这点我也废了很多时间,估计其他人也很可能遇到这样的情况。
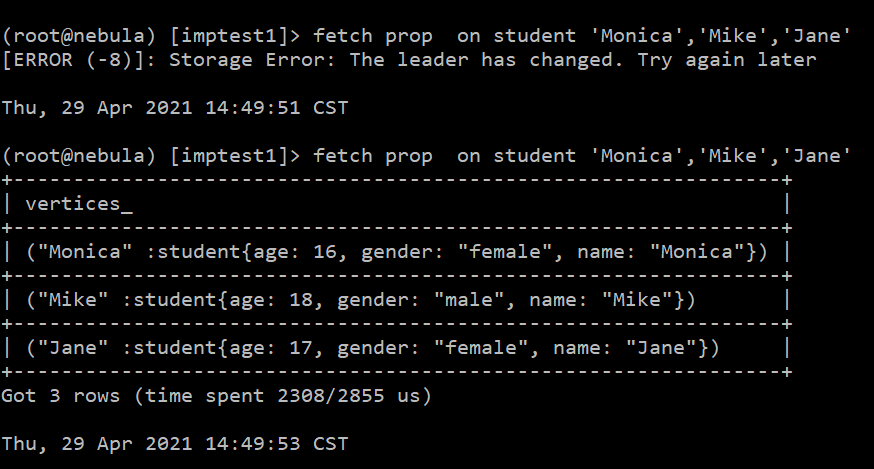
没有索引,那你就写代码把你csv里面id读出来,然后执行fetch prop on student id_list 是可以查出所有点的信息。
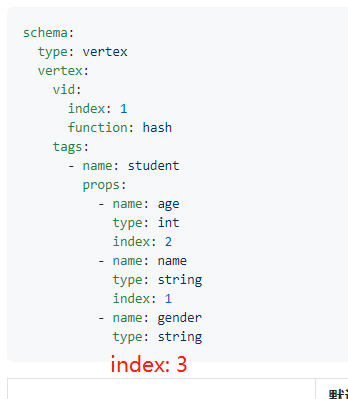
1、好像少了一行,
3、而且在example/v2/example.yml种你们的function:hash 都是注释的。这里为什么放开?建议示例要运行成功了再写上去。
4、我注释掉之后就能导入成功。
5.如果用的时hash 生成的VID 那么在不建立索引的情况下是不是几乎不可能查询具体的数据了?如果有办法查询到改怎么写查询语句呢?