1、是的,论坛有类似的问题,但是从你们的问答中并没有找到答案(如:https://discuss.nebula-graph.com.cn/t/topic/5324/15),且该帖已关闭,只能重新发贴。
回归问题本身,请教下,如果是spark环境下访问不了,那为什么可以通过spark写数据,但是通过其读数据就不行呢。
代码如下:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf
sparkConf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array[Class[_]](classOf[TCompactProtocol]))
val spark = SparkSession
.builder()
.master("local")
.config(sparkConf)
.getOrCreate()
writeVertex(spark)
// writeEdge(spark)
// updateVertex(spark)
// updateEdge(spark)
// deleteVertex(spark)
// deleteEdge(spark)
spark.close()
}
/**
* for this example, your nebula tag schema should have property names: name, age, born
* if your withVidAsProp is true, then tag schema also should have property name: id
*/
def writeVertex(spark: SparkSession): Unit = {
LOG.info("start to write nebula vertices")
val df = spark.read.json("example/src/main/resources/vertex")
df.show()
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("真实IP:9559")
.withGraphAddress("真实IP:9669")
.withConenctionRetry(2)
.build()
val nebulaWriteVertexConfig: WriteNebulaVertexConfig = WriteNebulaVertexConfig
.builder()
.withSpace("demo")
.withTag("person")
.withVidField("id")
.withVidAsProp(false)
.withBatch(1000)
.build()
df.write.nebula(config, nebulaWriteVertexConfig).writeVertices()
}
INFO [main] - Starting job: show at NebulaSparkWriterExample.scala:56
INFO [dag-scheduler-event-loop] - Got job 1 (show at NebulaSparkWriterExample.scala:56) with 1 output partitions
INFO [dag-scheduler-event-loop] - Final stage: ResultStage 1 (show at NebulaSparkWriterExample.scala:56)
INFO [dag-scheduler-event-loop] - Parents of final stage: List()
INFO [dag-scheduler-event-loop] - Missing parents: List()
INFO [dag-scheduler-event-loop] - Submitting ResultStage 1 (MapPartitionsRDD[6] at show at NebulaSparkWriterExample.scala:56), which has no missing parents
INFO [dag-scheduler-event-loop] - Block broadcast_3 stored as values in memory (estimated size 11.5 KB, free 893.8 MB)
INFO [dag-scheduler-event-loop] - Block broadcast_3_piece0 stored as bytes in memory (estimated size 6.0 KB, free 893.8 MB)
INFO [dispatcher-event-loop-1] - Added broadcast_3_piece0 in memory on DESKTOP-8V852AQ:60740 (size: 6.0 KB, free: 894.3 MB)
INFO [dag-scheduler-event-loop] - Created broadcast 3 from broadcast at DAGScheduler.scala:1161
INFO [dag-scheduler-event-loop] - Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[6] at show at NebulaSparkWriterExample.scala:56) (first 15 tasks are for partitions Vector(0))
INFO [dag-scheduler-event-loop] - Adding task set 1.0 with 1 tasks
INFO [dispatcher-event-loop-0] - Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, PROCESS_LOCAL, 8292 bytes)
INFO [Executor task launch worker for task 1] - Running task 0.0 in stage 1.0 (TID 1)
INFO [Executor task launch worker for task 1] - Code generated in 7.3107 ms
INFO [Executor task launch worker for task 1] - Finished task 0.0 in stage 1.0 (TID 1). 1469 bytes result sent to driver
INFO [task-result-getter-1] - Finished task 0.0 in stage 1.0 (TID 1) in 39 ms on localhost (executor driver) (1/1)
INFO [task-result-getter-1] - Removed TaskSet 1.0, whose tasks have all completed, from pool
INFO [dag-scheduler-event-loop] - ResultStage 1 (show at NebulaSparkWriterExample.scala:56) finished in 0.054 s
INFO [main] - Job 1 finished: show at NebulaSparkWriterExample.scala:56, took 0.056048 s
+---+----------+---+-----+
|age| born| id| name|
+---+----------+---+-----+
| 20|2000-01-01| 12| Tom|
| 21|1999-01-02| 13| Bob|
| 22|1998-01-03| 14| Jane|
| 23|1997-01-04| 15| Jena|
| 24|1996-01-05| 16| Nic|
| 25|1995-01-06| 17| Mei|
| 26|1994-01-07| 18| HH|
| 27|1993-01-08| 19|Tyler|
| 28|1992-01-09| 20| Ber|
| 29|1991-01-10| 21|Mercy|
+---+----------+---+-----+
INFO [main] - NebulaWriteVertexConfig={space=demo,tagName=person,vidField=id,vidPolicy=null,batch=1000,writeMode=insert}
INFO [main] - create writer
INFO [main] - Pruning directories with:
INFO [main] - Post-Scan Filters:
INFO [main] - Output Data Schema: struct<age: bigint, born: string, id: bigint, name: string ... 2 more fields>
INFO [main] - Pushed Filters:
INFO [main] - Block broadcast_4 stored as values in memory (estimated size 220.6 KB, free 893.6 MB)
INFO [main] - Block broadcast_4_piece0 stored as bytes in memory (estimated size 20.7 KB, free 893.6 MB)
INFO [dispatcher-event-loop-1] - Added broadcast_4_piece0 in memory on DESKTOP-8V852AQ:60740 (size: 20.7 KB, free: 894.2 MB)
INFO [main] - Created broadcast 4 from save at package.scala:248
INFO [main] - Planning scan with bin packing, max size: 4194847 bytes, open cost is considered as scanning 4194304 bytes.
INFO [main] - Start processing data source writer: com.vesoft.nebula.connector.writer.NebulaDataSourceVertexWriter@661d49d1. The input RDD has 1 partitions.
INFO [main] - Starting job: save at package.scala:248
INFO [dag-scheduler-event-loop] - Got job 2 (save at package.scala:248) with 1 output partitions
INFO [dag-scheduler-event-loop] - Final stage: ResultStage 2 (save at package.scala:248)
INFO [dag-scheduler-event-loop] - Parents of final stage: List()
INFO [dag-scheduler-event-loop] - Missing parents: List()
INFO [dag-scheduler-event-loop] - Submitting ResultStage 2 (MapPartitionsRDD[8] at save at package.scala:248), which has no missing parents
INFO [dag-scheduler-event-loop] - Block broadcast_5 stored as values in memory (estimated size 11.6 KB, free 893.6 MB)
INFO [dag-scheduler-event-loop] - Block broadcast_5_piece0 stored as bytes in memory (estimated size 6.7 KB, free 893.6 MB)
INFO [dispatcher-event-loop-0] - Added broadcast_5_piece0 in memory on DESKTOP-8V852AQ:60740 (size: 6.7 KB, free: 894.2 MB)
INFO [dag-scheduler-event-loop] - Created broadcast 5 from broadcast at DAGScheduler.scala:1161
INFO [dag-scheduler-event-loop] - Submitting 1 missing tasks from ResultStage 2 (MapPartitionsRDD[8] at save at package.scala:248) (first 15 tasks are for partitions Vector(0))
INFO [dag-scheduler-event-loop] - Adding task set 2.0 with 1 tasks
INFO [dispatcher-event-loop-1] - Starting task 0.0 in stage 2.0 (TID 2, localhost, executor driver, partition 0, PROCESS_LOCAL, 8292 bytes)
INFO [Executor task launch worker for task 2] - Running task 0.0 in stage 2.0 (TID 2)
INFO [Executor task launch worker for task 2] - switch space demo
INFO [Executor task launch worker for task 2] - Commit authorized for partition 0 (task 2, attempt 0, stage 2.0)
INFO [Executor task launch worker for task 2] - batch write succeed
INFO [Executor task launch worker for task 2] - Committed partition 0 (task 2, attempt 0, stage 2.0)
INFO [Executor task launch worker for task 2] - Finished task 0.0 in stage 2.0 (TID 2). 1124 bytes result sent to driver
INFO [task-result-getter-2] - Finished task 0.0 in stage 2.0 (TID 2) in 464 ms on localhost (executor driver) (1/1)
INFO [task-result-getter-2] - Removed TaskSet 2.0, whose tasks have all completed, from pool
INFO [dag-scheduler-event-loop] - ResultStage 2 (save at package.scala:248) finished in 0.477 s
INFO [main] - Job 2 finished: save at package.scala:248, took 0.478719 s
INFO [main] - Data source writer com.vesoft.nebula.connector.writer.NebulaDataSourceVertexWriter@661d49d1 is committing.
INFO [main] - failed execs:
List()
INFO [main] - Data source writer com.vesoft.nebula.connector.writer.NebulaDataSourceVertexWriter@661d49d1 committed.
INFO [main] - Stopped Spark@47a7a101{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
INFO [main] - Stopped Spark web UI at http://DESKTOP-8V852AQ:4040
INFO [dispatcher-event-loop-1] - MapOutputTrackerMasterEndpoint stopped!
INFO [main] - MemoryStore cleared
INFO [main] - BlockManager stopped
INFO [main] - BlockManagerMaster stopped
INFO [dispatcher-event-loop-0] - OutputCommitCoordinator stopped!
INFO [main] - Successfully stopped SparkContext
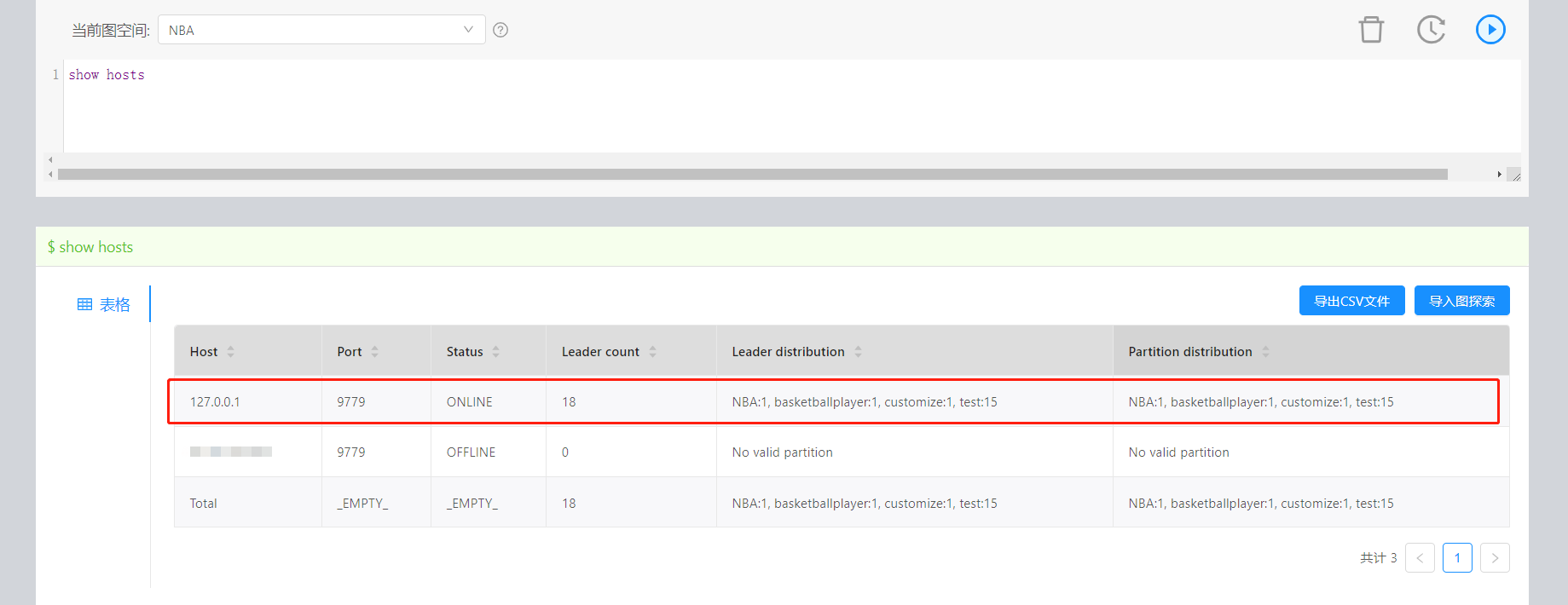
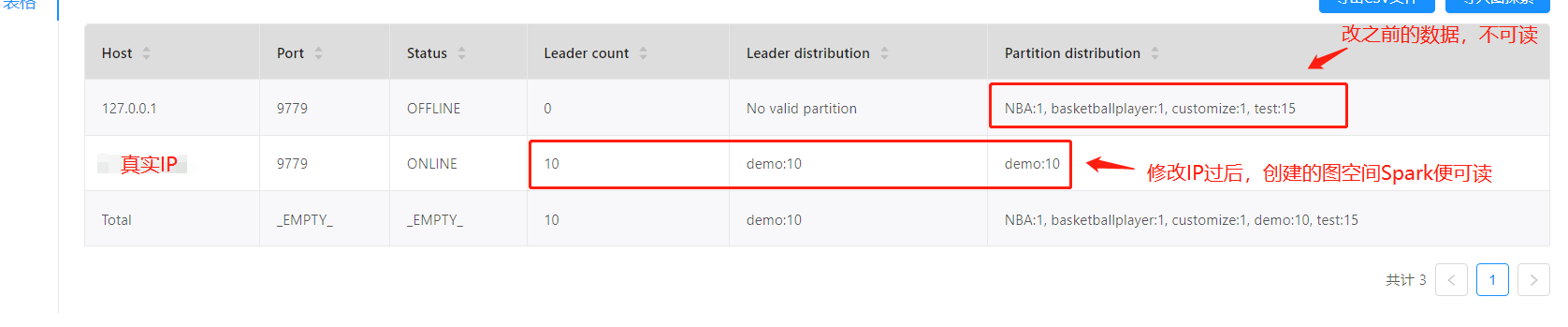
show hosts如下:
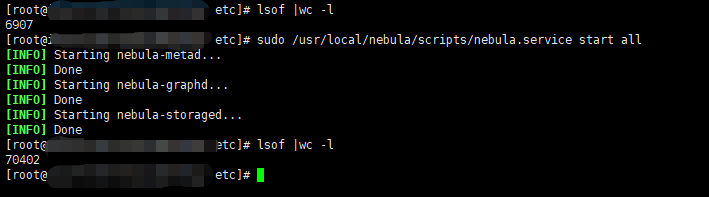
2、关于发open files问题,我觉得和该问题可能存在必要的联系,故发出来方便你们排查定位。如无因果关系,请忽略 ^-^'。