
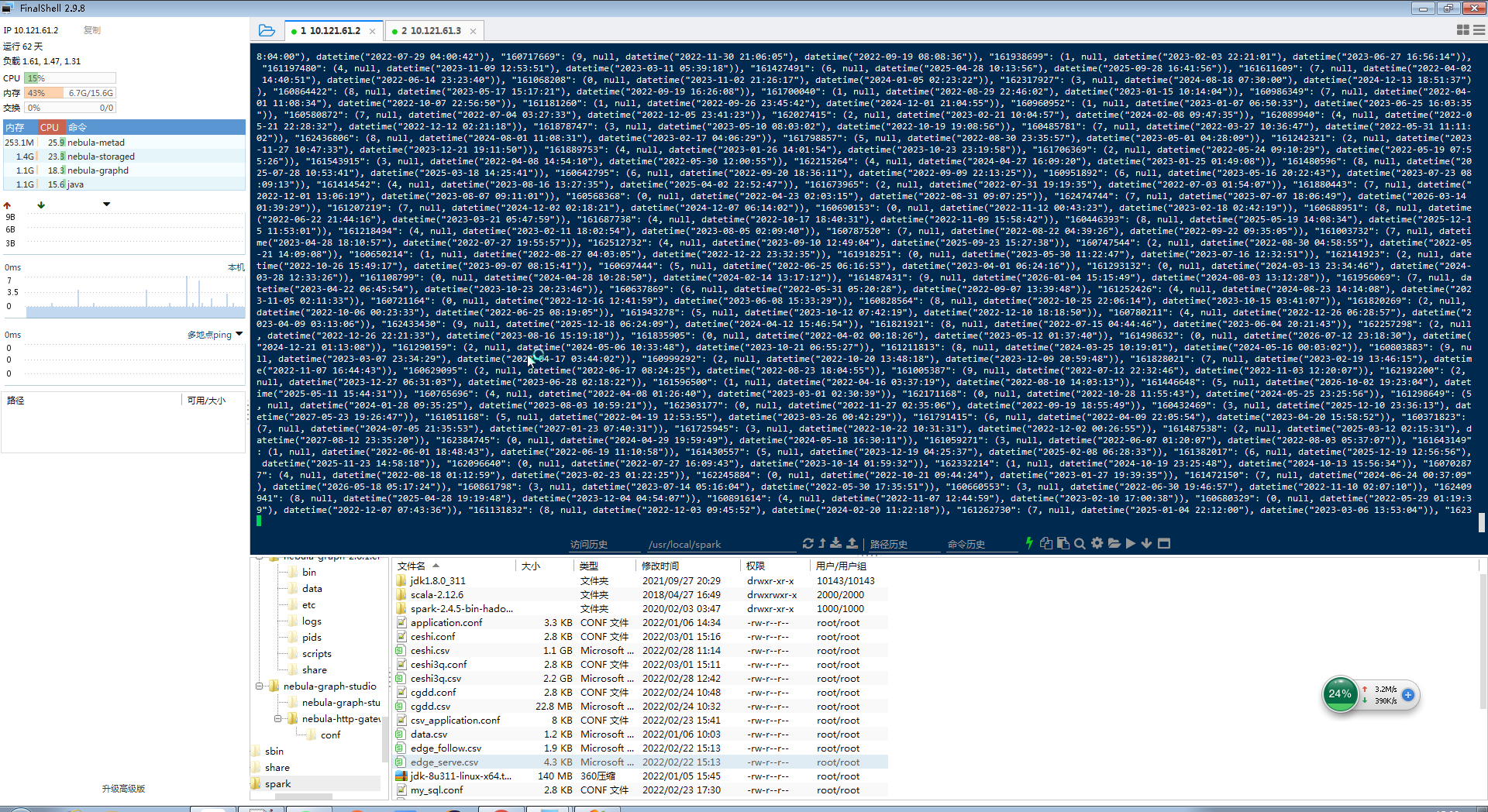
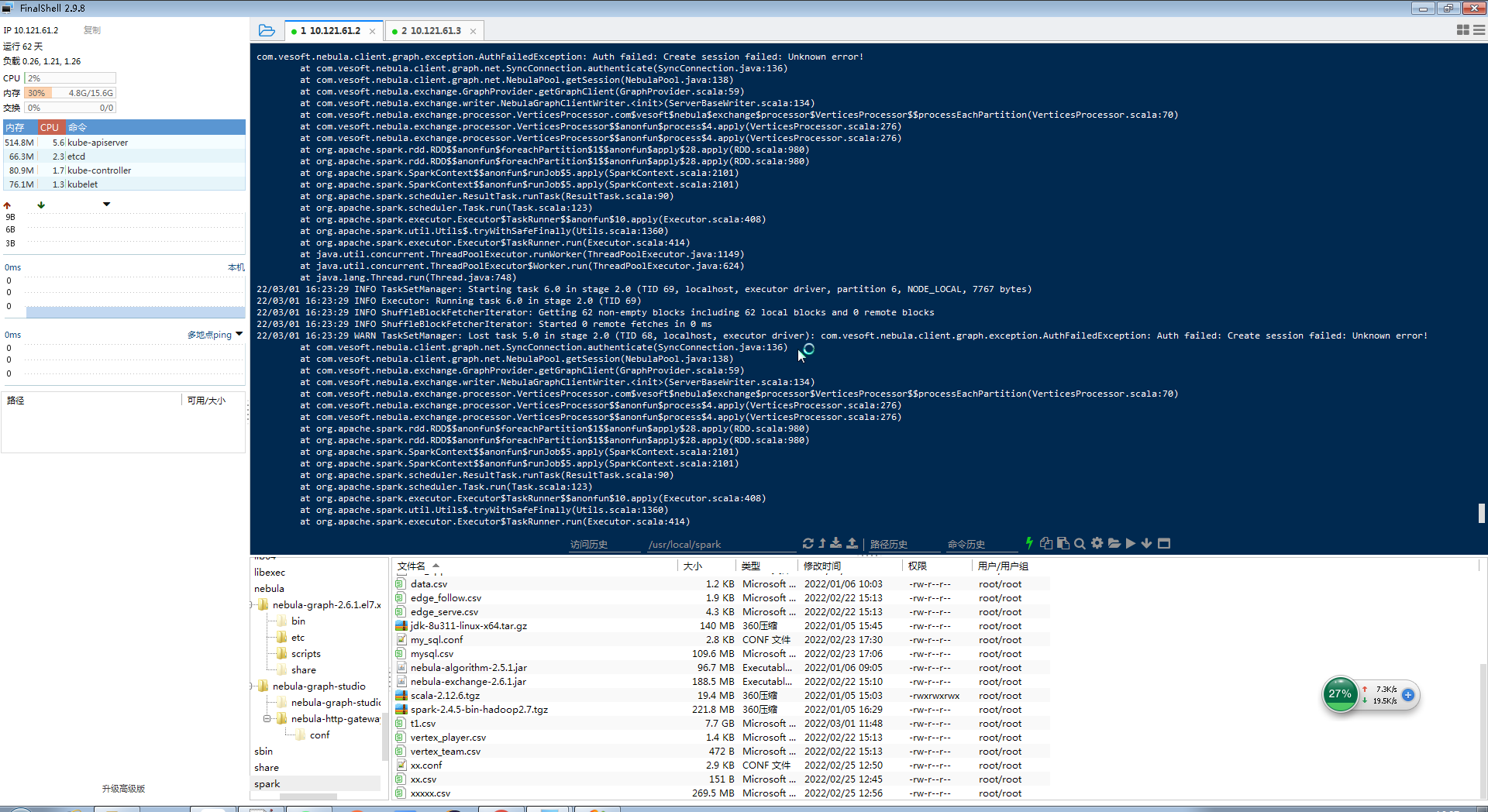
亿级数据单tag导入,用的spark2.4.5,nebula是2.6.1,nebula-exchange2.6.1,导入报错截图如下



计划是亿极数据导入性能能测试,目前是单tag,后面会增加关系edge,边的数据会成倍增加
先看下防火墙是不是开放了指定端口吧
Graph 进程还在吗?
我看是 create session 失败的 Meta 进程都在吧
进程都在,就是导入部分数据后就报错了,很奇怪
如果之前数据写进去了 那说明配置没问题 网络应该也没问题 如果进程都在 那就不知道为啥了
额,问下exchange最大支持导入多少数据?
你的量级是可以支持的
哪有成功的时间么,我主要想知道亿级导入需要多久,和导入亿级数据后match查询的速度如何,还有边的查询速度怎么,一跳和三跳四跳的速度怎么样?

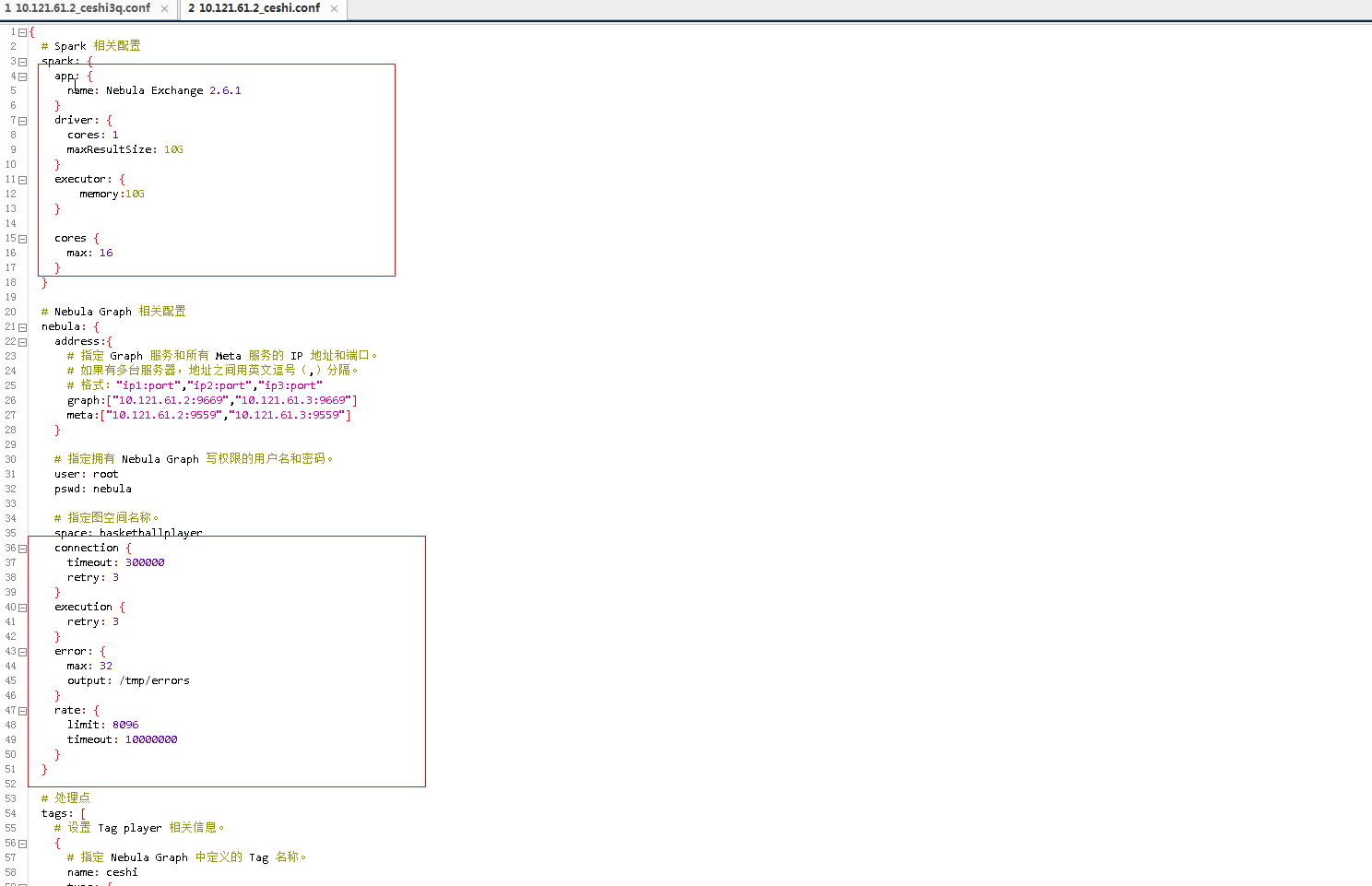
参数说明在这里

这两个没有经验值 你可以选择默认值
这我看不出来 …… 执行结果如果说格式错误那就是数据的问题了
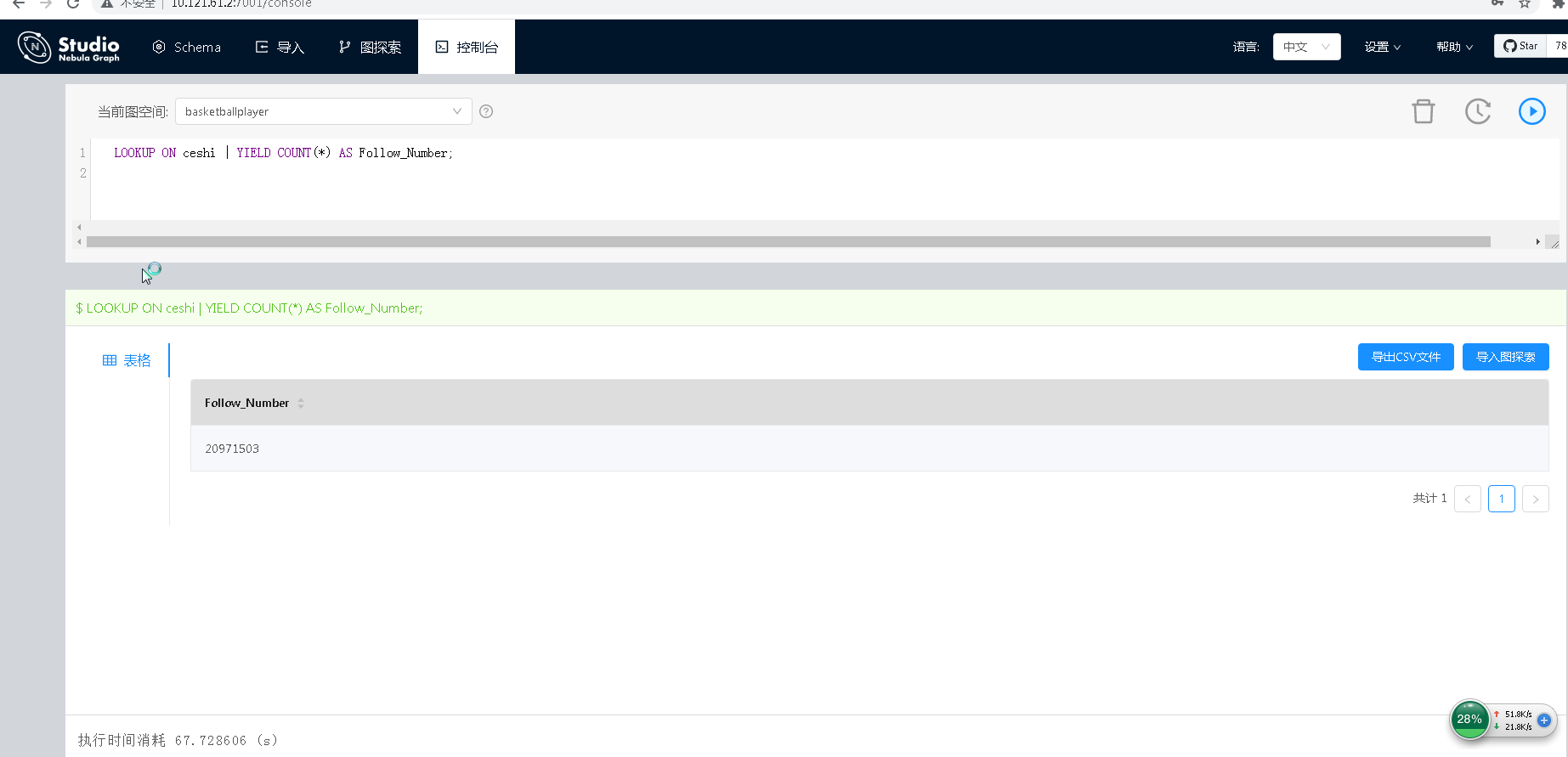
这么小的数据量,直接用importer好了