业务使用 Spark 对 Nebula (2.6.1) 进行数据导入时,发现系统内存持续增长,且不释放,具体情况如下图所示:

尝试解决
起手·配置文件
查看 Nebula 官网文档之后,对 nebula-storaged.conf 配置文件中的 --rocksdb_block_cache 进行调整,设置为 4M 大小,但是结果显示依旧同之前一样占用大量内存。继而继续调整配置项,设置 enable_partitioned_index_filter=true,问题依旧没有解决。
这里提一嘴 Nebula 的 RocksDB 实现,Nebula 底层存储引擎用的 Rocksdb,通过上面的参数设置 rocksdb_block_cache 对应 RocksDB block_cache 实例缓存未压缩块、enable_partitioned_index_filter 对应 pin_l0_filter_and_index_blocks_in_cache,在 Nebula 中只对 RocksDB 第 L0 层 SST 文件开启了索引(index block)和布隆过滤(filter block)缓存,在其他层不进行缓存。
配置完 enable_partitioned_index_filter=true 理论上存储不会占用很多内存,但是内存占用量仍旧持续不减,猜想可能是某个进程占用了内存,可以通过剖析工具去定位哪里占用了内存。
验证猜想
在网上找到相关资料后,用内存分配器 jemollc 自带的 jeprof 工具收集内存分配信息,生成 jeprof.*heap 文件进行内存占用量分析。参考以下命令:
MALLOC_CONF="prof:true,lg_prof_interval:26" LD_PRELOAD="/usr/lib64/libjemalloc.so.2" /usr/local/nebula/bin/nebula-storaged --flagfile /usr/local/nebula/etc/nebula-storaged.conf
再通过 jeprof 读取生成的 jeprof.*heap 文件:
jeprof /usr/local/nebula/bin/nebula-storaged jeprof.*
(jeprof) top
Total: 18903464.5 MB
13371403.1 70.7% 70.7% 13371403.1 70.7% rocksdb::UncompressBlockContentsForCompressionType
5503821.4 29.1% 99.9% 18875224.5 99.9% rocksdb::BlockFetcher::ReadBlockContents
5923.5 0.0% 99.9% 6518.4 0.0% rocksdb::LRUCacheShard::Insert
4704.0 0.0% 99.9% 4704.0 0.0% std::__cxx11::basic_string::_M_mutate
3257.7 0.0% 99.9% 10664.1 0.1% rocksdb::BlockBasedTable::PutDataBlockToCache
2964.1 0.0% 99.9% 3261.7 0.0% std::__detail::_Map_base::operator[]
2085.1 0.0% 100.0% 2085.1 0.0% rocksdb::VersionBuilder::Rep::ApplyFileAddition
1714.6 0.0% 100.0% 1714.6 0.0% std::_Rb_tree::_M_insert_unique
1483.0 0.0% 100.0% 1783.5 0.0% nebula::meta::MetaClient::loadSessions
这里我们看到上面 RocksDB 报了个 UncompressBlockContentsForCompressionType,将该提示符去 Rock s DB 的 GitHub 检索下,看能发现什么?在 GitHub 的 issue:https://github.com/facebook/rocksdb/issues/4112 中有用户通过设置参数 max_open_files 为 20 降低了内存。所以我们也来试试。
然而设置完 max_open_files 为 20 之后,内存占用依旧高。继续用 jeprof 来分析下内存占用;
这里提下 jeprof 生成的内存 profile 支持 PDF、SVG 等多种格式。由于 jeprof 生成的 PDF 可看到调用链,因此这里我采用了 PDF 格式。
jeprof --pdf /usr/local/nebula/bin/nebula-storaged jeprof.* > nebula-storaged.pdf
从生成的 PDF 中,我发现是 PartitionIndexReader、PartitionedFilterBlockReader 进程占用内存高:
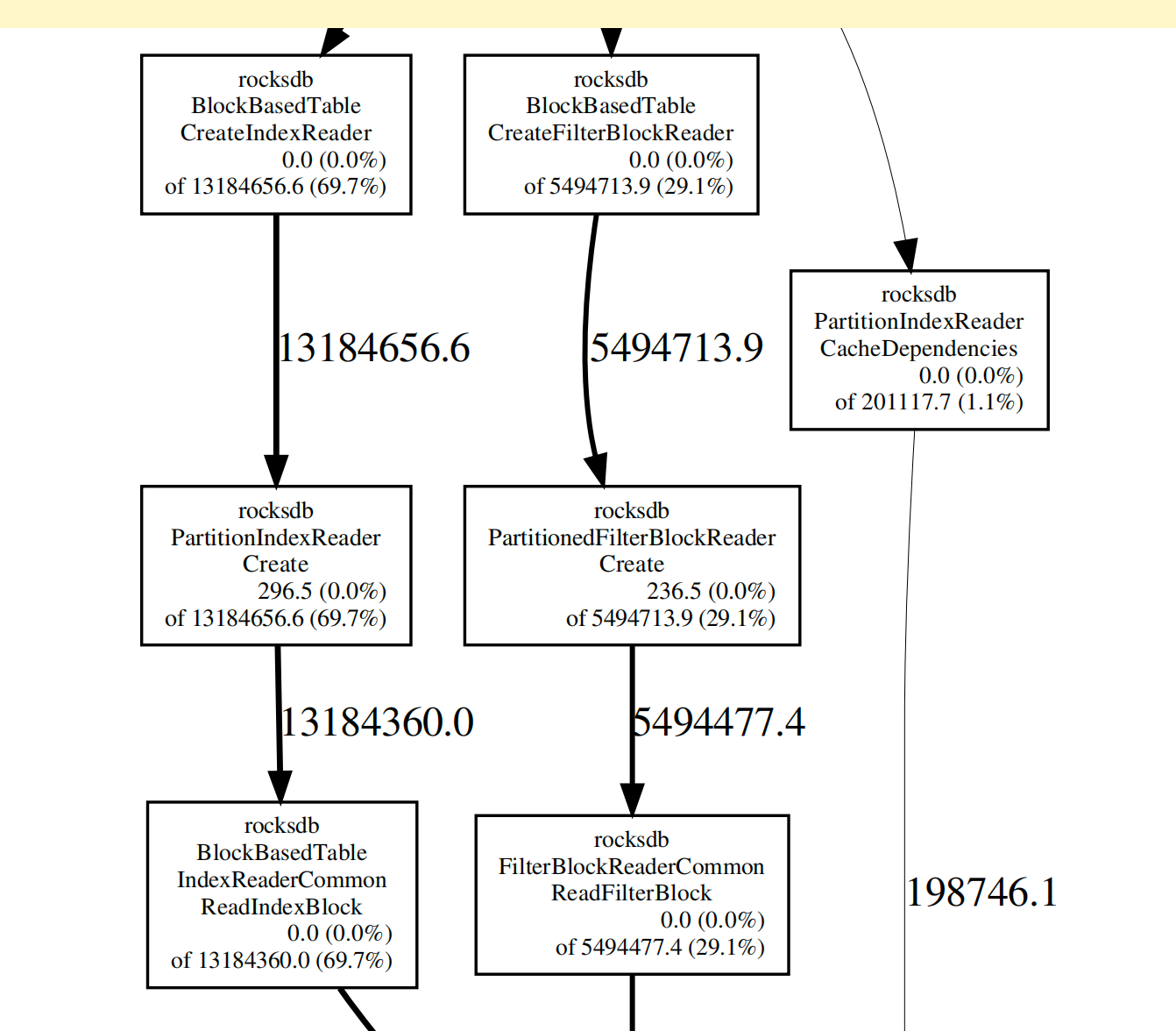
具体的 PDF 可查看附件:
nebula.pdf (15.3 KB)
最后一击
这里要搬出程序员的背后大佬——搜索引擎了,通过谷歌检索 rocksdb PartitionIndexReader high memory,好的,找到了一个相关连接:http://rocksdb.org/blog/2017/05/12/partitioned-index-filter.html。
来看看这个 url 里面有什么——"cache_index_and_filter_blocks,通过设置cache_index_and_filter_blocks:false,再重启 nebula-storage 进程,内存终于降下去了。
查看 RocksDB 官网:https://github.com/facebook/rocksdb/wiki/Memory-usage-in-RocksDB 这块对 “RocksDB memory used” 内容的讲解:如果你设置 cache_index_and_filter_blocks 为 true,索引和过滤块会被存储在块缓存,跟其他数据块一起;如果设置成 cache_index_and_filter_blocks:false,此时 index 和 filter 这边内存占用量并会释放(因为不占用内存)。
但设置 cache_index_and_filter_blocks:false 会降低性能,这里在开启缓存之后,尝试调整参数找到性能平衡点:通过调大 block_size,增加块大小,降低块的数量,故而线性减少索引的大小。
尝试调大 block_size 到 32768,降低 max_open_files 到 50000,重启 nebula-storage:很好,内存使用率保持在比较低的水平。
这里要提醒下各位不要设置 max_open_files 参数设为 -1,在 max_open_files=-1 设定下其他参数做任何调整都不起作用。
还有一个优化内存的点:可修改布隆过滤器为 Ribbon Filter,可优化内存。但该修改会增高 CPU 消耗,这里并没有进行相关调整,仅配置做了这两个参数的调整:max_open_files:50000、block_size:32768。修改如下:
--rocksdb_db_options={"max_subcompactions":"4","max_background_jobs":"4","max_open_files":"50000"}
--rocksdb_block_based_table_options={"block_size":"32768","cache_index_and_filter_blocks":"true"}
至此,问题解决。
参考文献:
