由于微信群的封闭性,很多新加群的小伙伴表示检索不到群里之前的讨论记录
,NebulaGraph 迷人的小姐姐在此收集了群里那些热门的讨论,以方便大家相似问题的检索~ 同时也欢迎大家对整个话题集或者下列的讨论进行完善和补充哦
~
话题集锦
小N:我有一个特殊点有超过三千万个邻居,在执行这个语句时候会报错:[ERROR (-1005)]: Storage Error: part: 5, error: E_RPC_FAILURE(-3).
GO 1 STEPS FROM “-5497497974970769875” OVER follow YIELD id($$) as id, properties(edge).dt as dt |ORDER by $-.dt | limit 5;
当其中增加了limit时,就不会有这样的错误。
GO 1 STEPS FROM “-5497497974970769875” OVER follow YIELD id($$) as id, properties(edge).dt as dt | limit 10000 |ORDER by $-.dt | limit 5;
小B:go 上每一步可以 limit,另外在全局也有可以截断拓展最大出边的配置(但是要小心设置值免得影响正确性) 搜超级节点应该能找到那个配置。如果保持仅仅是超时了,那个timer 也能配置,在graphd 的配置里 */保持/报错/
小N:storaged服务,存储挂载是需要NFS这种么,还是单纯的云盘就可以
小B:推荐ssd云盘
小N:除了nGQL语法,还能使用什么语法去查询nebula?
小B:狭义的 nGQL 就是 GO, FETCH, LOOKUP, GET SUBGRAPH, FIND PATH,和插入更新删除语句(DML)。广义的 nGQL 还加上 openCypher 的 DQL(MATCH)
https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/1.nGQL-overview/1.overview/
这些都是通过 graphD 的 query,在需要分析全图数据的时候,通过 storageclient 连接 metad 和 storaged 也可以扫全图数据(按照 tag/edge type)
小N:想部署nebula,想问问推荐部署的方式是怎样的,meta的存储和storage的存储需要分开放到不同的SSD中吗?
小B:这个我觉得是有资源就建议分开来,没资源就放同一个SSD里,没有太大影响,丰俭由人
小N:感谢,还有就是,想了解一下,大家通用的配置是怎样的,磁盘总存储不变的话,磁盘数是多一些好还是有一个比较合适的阈值,比如单台机器总磁盘大小为7T左右, 是2块3.5T的好,还是4块1.6T的好一些?
小U:按官方文档的说法,应该是多磁盘并发后,性能更好一些
小N:nebula资源规划这块有了解的么,例如,是根据用户量,日活。数据存储需要多少
小B:可以参考下文档:https://docs.nebula-graph.com.cn/3.2.0/4.deployment-and-installation/1.resource-preparations/
小N:lookup on 语句指定了tag,就只能查顶点在这个tag下的属性,其他tag中的属性就查不到,这是不是不太合理?properties(v)这种,在其他地方都是可以查出这个点的所有属性的,但是如果用了lookup语句,那就只能查出某个tag下的属性了
小B:主要是我们现在的逻辑是,属性是挂在tag下的。指定了tag就限定了属性的范围。
小N:那我用 match (v:graph) return properties(v) 这种,是可以查出所有属性的,而不是graph这个tag下的属性
小B:这是个好问题。我理解,这里的逻辑是“满足这个点条件”的属性;lookup的逻辑是“查找这个tag的属性”,两个不太一样
小N:我只是觉得properties(v) 这种,在不同的查询语句下,还不太一样。有时候有点莫名其妙,明明有这个属性?怎么找不到?还以为是写的不对
还有就是,删除支持管道符连接,但是修改不支持,这也不太符合常理
小B: 这个确实是,主要是考虑修改可能修改成不同的值
小N:NebulaGraph VEditor有详细点的文档嘛? 比如说详细的api使用文档
小B: 目前建议通过 ts 定义,和仓库提供的 demo 尝试。之后会有更详细的文档出来,敬请期待~
小N:https://docs.nebula-graph.com.cn/3.1.0/nebula-exchange/use-exchange/ex-ug-import-from-sst/ 我看这个能把csv处理成sst 再导入nebula,那能maxcompute处理成sst 再导入nebula 吗
小B:我觉得是可以的,但没实际操作过。。。但至少maxcompute是可以生成csv的
小N:不知道为啥会出现这个情况
到nebula graph中吗
小B:数据源是 csv 的话,可以用 nebula importer,exchange 还支持其他数据源,还有几个其他的客户端/connector 文档里有介绍
https://docs.nebula-graph.com.cn/3.1.0/20.appendix/write-tools/
我这个图/视频也有介不同工具的选择 https://www.siwei.io/sketches/nebula-data-import-options/
小N:go 2 stops from 这样查两跳的语句 为啥连一跳的节点也查出来了?
小B: 应该是有别的2跳能到这个点
小N:怎么在一条语句里去重啊。我现在是用了 minus 好像也能实现
小B:minus很好
小U: 可是为啥不用distinct?
小N:用户填写的居住地址或者单位名称这种做id表示为节点,大佬们有啥方案吗? 感觉这种情况是不是只能当属性,没法建立节点。
小B:没办法不重复吧,你这怎么当id啊
小U: 居住地址用string即可,但要保证全局唯一;
不行的话也可以hash成id;
重复的话我理解就是同一个人了
小N:请问线上热新增tag的prop,查询会有短暂的报错 这种是什么原因呀
小B:我昨天操作的时候,出现的说是让稍等2个周期,再进行查询,不知道和你这个问题一样吗
小U: 应该是同一个问题,对schema的操作是异步的。这个问题大家吐槽很久了。
小N:请教一下,这里为什么要用异步请求,是有什么考量吗
小L:性能和简单
小U: 但是用户体验很不好,也会带来很多问题
小L:是 这个我们也是有很大痛点
小A:图数据库的schema不是固定好的,后期肯定会动态新增、删除、修改
小L:是的,就是看schema是有限制修改还是 需要和插入数据一样
小E:schema应该在最开始时候设计好,不应该频繁修改
小L:不大可能 会有修改的场景,但是频繁谈不上
小U: 修改不多,但是动态新增绝对多
小B:不频繁我认可,但是肯定支持
小L:但是哪怕是不多
小U: 你们知道rdfs吗?导入rdfs的时候,是需要建schema 的
小E:嗯嗯 schemaFul 的设计是一个面向性能的折中,nebula面向的数据量去设计,走了强schema的方向,带来了性能优势。不过 schema change 这里确实有空间做的体验更好,可以考虑比如在心跳基础上增加一个push广播的(best effort)的 schema change
小 N:而且感觉也会影响别的tag吗 我们只修改了device这个tag 但是别的tag查询似乎也受到了影响
小E: 确实会的,因为对于graphd和storaged来说是拿了一个metaclient
小B:添加新的tag 不影响查询的,但是感觉有一些痛点
小 N:USE account_risk_graph;MATCH (v:aid{aid:‘175724423’}) RETURN v, ErrorCode: -1005, ErrorMsg: Storage Error: Tag prop not found.
小 N: 但我看了下这个vid 只关联了aid这个tag
小B:为啥也会影响别的tag相关的点呢
小 N:return v 的时候会扫所有的 tag和 无tag,这处在了中间阶段
小B:如果刚好在更新,就会获取不到数据,以及思为说的情况
小B:感觉这里也有优化的空间,是不是可以做到增量添加元信息
小 N:好吧 有好的解决思路吗 我们想保证查询没错误 比如 如果不alter tag 而是新增tag会影响吗
小U:只能sleep,等待结束,两个心跳
小N:想了解对nebula建的图谱进行推理补全,有相关资料吗?比如逻辑推理方法,工具的话有jean推理机等
小B:看下 中科大脑知识图谱平台建设及业务实践 或者 https://www.siwei.io/siwi
对你有没有参考?刚问了研发小哥,他说他理解属性图模型下,这些推理是自己实现的 问题 到 属性图库 Query 的转译去做的
向nebula下导入数据 可以支持RDF的三元组吗或除了csv格式的还有哪些格式呢
不支持RDF的三元组哈,可以转成 CSV 的格式
Hello,各位大佬。我有一事不明。。。在服务架构/Storage服务中有提及Storage最终是写入到RocksDB,但是在安装部署的文档中并没有提及对RocksDB的安装。是不是意味着,当我在各个节点安装好nebula的包后,在相应的节点启动storaged进程就可以了,storaged进程内部就包含一个RocksDB呢?
是的,storaged 里面使用了 RocksDB,用户不需要额外部署 RocksDB。
那storaged的数量要求为单数吗?
参考 https://docs.nebula-graph.com.cn/3.2.0/20.appendix/0.FAQ/#create_spacereplica_factor_2
https://docs.nebula-graph.com.cn/3.2.0/4.deployment-and-installation/1.resource-preparations/#_14
请教一下大佬,如果指定属性查,不加索引是不是就没有办法加
where条件?
是的,match 查不行吧
是的
有没有啥其他办法
捞出来数据 客户端做filter 如果实在没索引的话
那数据量太大了,几千万怎么客户端做filter
不然想不到别的办法 感觉内核可以出一些对不建立索引查的方法。你们做实时 还是 离线分析
实时
不加索引主要是影响插入效率
这个没索引查确实比较痛。连scan都不让了,主要是存算分离。
是加了索引影响插入效率吧
如果没有做下推的逻辑内部网络rpc受不了
嗯嗯
其实看你的数据量
可以测试一下
测了,根本写不进去
如果说有索引可以满足你的插入效率
写不进去?多大数据量啊
上亿
你这个基于tag过滤后的数据也很大么。你们实时的数据有那么大么,据我了解 加上index 应该不至于性能那么差
之前用的是neo4j。三千万,真写不进去。指定VID应该可以吧
这个是可以的
建了索引。200万点300万边importer导入的话要1分钟
我用数据量不大基本也就56百万数据,索引影响不大
如果在某一个tag 上面建索引,会不会影响其他tag数据写入?
不会 这个一定是不会的
你数据量大,你要多建几个分片
是的,目前是这么考虑的
用spark写数据
索引和备份数影响写入性能,越多越慢。我是把分区数跟rdd分区数齐平去写的,几千万的数据用30个片写的很快。
加了索引了吗
有的,有五六个
主要是查的时候最好别用match,用lookup
明白,谢谢
SSD是必须的吗?
不是
数据导入csv文件时^C不能作为分隔符吧,数据从GaussDB卸下来以^C做为分隔符的
importer里可以指定分隔符的,试过么?
在yaml文件里指定了^C,导入时失败,control character are not allowed
exchange支持一个character作为分隔符,^C是两个字符不行。需要的话用spark conenctor 去导入是可以的
^C是一个字符吧,在键盘上按Ctrl+V+C打出来的
看报错只是 yaml 格式的问题,括号包裹起来呢?也可以试试 “\003” 么?或者 “\cc” ; delimiter: “\003” 或者 delimiter: “\cc”
有什么的写cypher的编辑器吗,没高亮写着难受啊
![]() 欢迎试用 https://marketplace.visualstudio.com/items?itemName=wey-gu.vscode-ngql
欢迎试用 https://marketplace.visualstudio.com/items?itemName=wey-gu.vscode-ngql
社区版本,match查询的时候是全部数据扫描吗?内存不够大会返回数据吗?我们用match查询没有返回数据,无法判断是否都成为了悬挂边,创建其他空间,导入少量数据match查询数据是正常的
用lookup查一查
lookup查的到,但是lookup本来就支持查询悬挂边的,所以不知道是否已经成了悬挂边
请问 这个配置 改了
也重启了为啥 还是 报错误呢
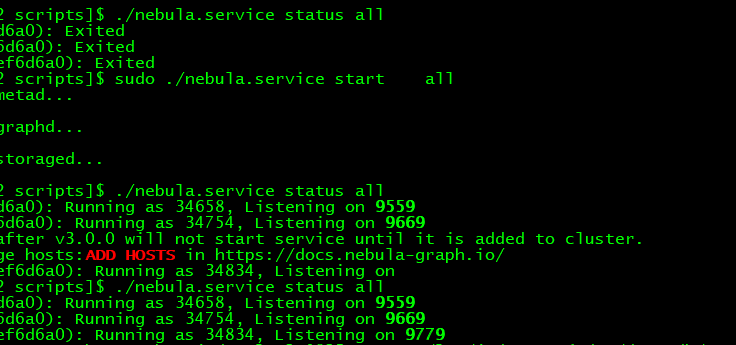


是我重启的方式不对吗,有佬来解释下嘛
配置前边的 两个减号是不是没写?
惯性思维了,以为是注释
哈哈,这里确实有点违反常识,不过其实它们是 https://github.com/gflags/gflags
我想咨询一下问题, nebula 3.2集群版本,我用过graphd或者stroage把数据写入图空间,能实时查出来么?会不会异步写有延迟导致下一次查询差不到的情况
可以的。不会延时。 nebulagraph 是实时同步写入的
graphd和stroage都是实时吗?
是的
好的好的,感谢大佬
大佬问求个问题:v3.1.0版本,我用match语句查询数据,返回字段value被替换成了values。这是为啥呢?
来个图看看
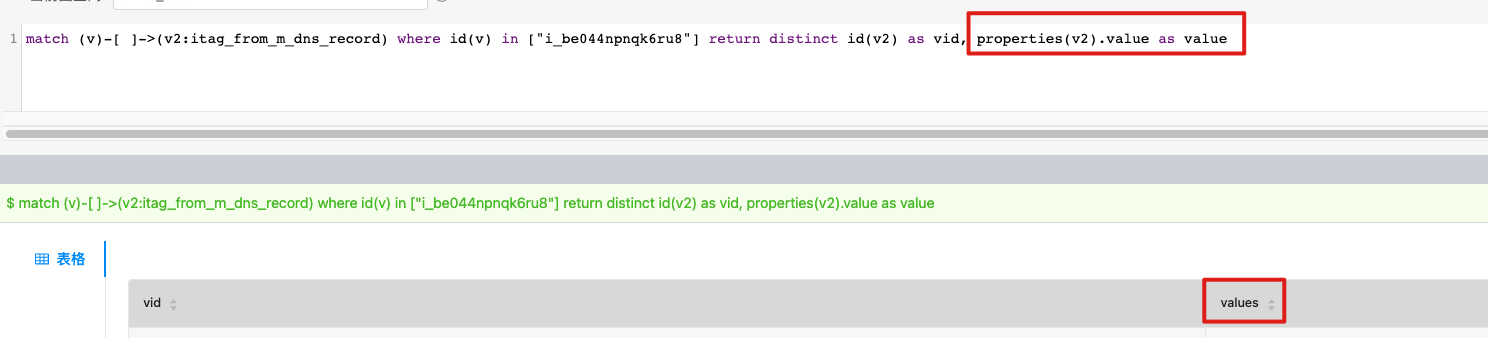
我看模型里面也是存储的values
我记得3.1的match是有一些bug的,你可以试试3.0
使用value也可以拿出数据,我试下
关于生产版本 3.0.0,是不是有必要升级最新版3.2.0 你可以看看这个帖子,上次咱们讨论过。3.1的match做了一些优化,还存在一些bug。

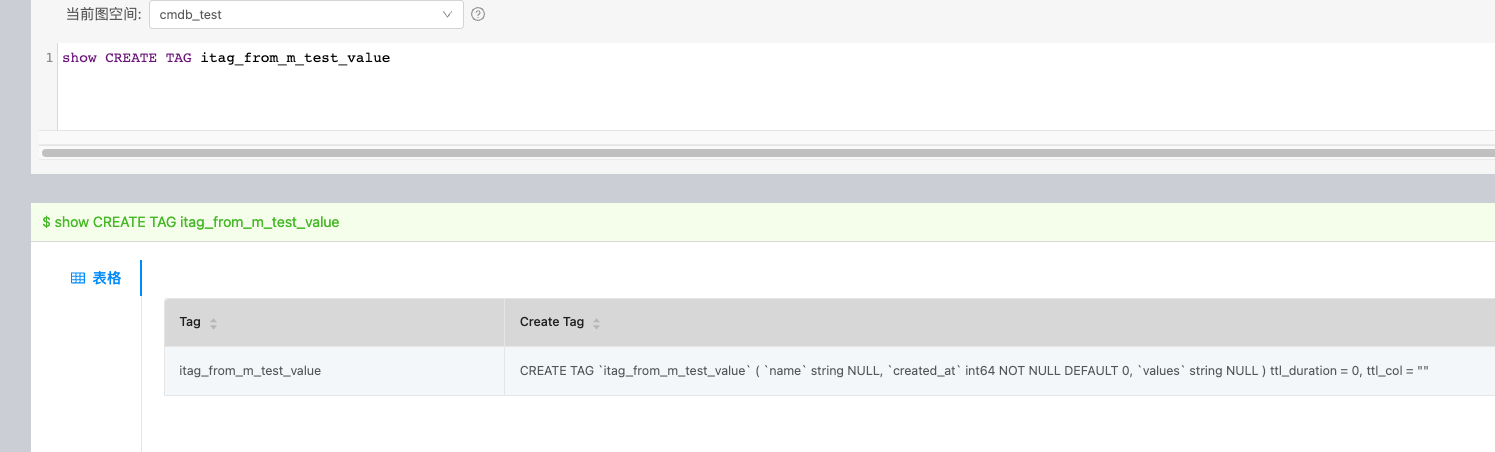
不是match的bug。CREATE TAG itag_from_m_test_value(name string, created_at int64 NOT NULL DEFAULT 0, value string); CREATE TAG itag_from_m_test_value ( name string NULL, created_at int64 NOT NULL DEFAULT 0, values string NULL ) ttl_duration = 0, ttl_col = “”
是你自己创建的时候写错了对吧

没写错,写对了到库里就错了,我写的是这个,结果是上面报错的截图
nebula jdbc现在不支持参数化insert是吗
在数据库层面,现在 nebula dml 本身没支持(像cypher那种的)参数化哈。
不过我看 nebula-jdbc 例子里是拼接的 insert 语句,不能满足你的需求么?
// get PreparedStatement, set configuration parameters and execute
String insertPreparedStatementNgql = "INSERT VERTEX testNode (theString, theInt, theDouble, theTrueBool, theFalseBool, theDate, theTime, theDatetime) VALUES " +
""testNode_8":(?, ?, ?, ?, ?, ?, ?, ?); ";
PreparedStatement insertPreparedStatement = connection.prepareStatement(insertPreparedStatementNgql);
insertPreparedStatement.setString(1, “YYDS”);
insertPreparedStatement.setInt(2, 98);
insertPreparedStatement.setDouble(3, 12.56);
insertPreparedStatement.setBoolean(4, true);
insertPreparedStatement.setBoolean(5, false);
insertPreparedStatement.setDate(6, Date.valueOf(“1949-10-01”));
insertPreparedStatement.setTime(7, Time.valueOf(“15:00:00”));
// make a class cast and then call setDatetime
NebulaPreparedStatement nebulaPreparedStatement = (NebulaPreparedStatement) insertPreparedStatement;
nebulaPreparedStatement.setDatetime(8, new java.util.Date());
insertPreparedStatement.execute();
这个预编译的statement是自己写的吗?我好像没法从session的api里得到?
这个是 nebula-jdbc 已经提供的 query string construction,我贴的是它的 readme;nebula-jdbc 没用 execute_with_parameter 的方法还,是client 这边攒的 query string。不过 insert 服务端现在是不支持参数的哈
我一直用的都是nebula pool,这个nebula driver好像本身就具备pool的功能
我以为你说的是 https://github.com/nebula-contrib/nebula-jdbc 这个项目
我说的是client的项目,没想到这俩居然不一样
https://github.com/nebula-contrib/nebula-jdbc 是基于 nebula-java 的 jdbc 封装。如果你说nebula-java 的参数化的话,数据库那边,insert 语句还不支持参数化。
com.vesoft.client这个项目就是nebula java吗?
对的
噢,好的,我研究下这个。我用的client,就发现拼接一个insert语句,里面有换行符就不行。nebula jdbc返回的是标准的resultset,就没法用asnode这种语法了。
请问各位大佬单机模式部署的 nebula ,其性能受切片数量影响大吗?
你说part?我个人感觉 那就看磁盘个数了

spark connector 从hive 导入一直卡顿状态,什么情况?
小文件太多了?
我sparksql查hive后的那个dateframe repartion ( 200)了已经
感觉4900多节点,跑5s,是不是有点慢了,但是又想不到什么优化的手段了;目前这些数据的结构是树状结构,有统一的根节点,但是不是平衡的,想要找到全部的叶节点;感觉除了遍历,就只能在存储阶段做操作了
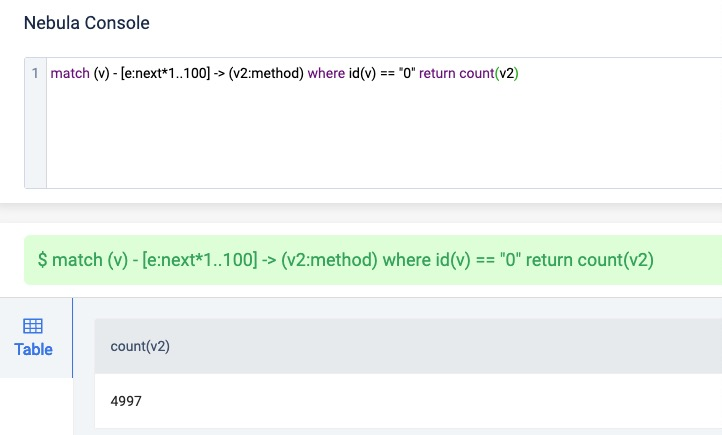
用get subgraph试试
老师 我最近在看你们的源码 我是新手 有些问题想请教一下 1.在common/datatypes/geography中,.h or .cpp的是不是为了方便对接地理数据库? 2.在common/datatypes/VertexOps-inl.h、ValueOps-inl.h等*-inl.h是不是service服务端对thrift相应函数的重载、读写、封装(Binary、JSON 等)
1 是原生的geo spatial 的类型支持 https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/3.data-types/10.geography/
求问下有图数据库在安全领域的落地实现的相关资料吗
请问安全领域具体指?
比如威胁分析,攻击者画像之类的
可以看这篇博客:百亿级图数据在快手安全情报的应用与挑战 百亿级图数据在快手安全情报的应用与挑战
悬挂边就是没有出度和入的边,不和任何点关联,是这个意思吧

https://www.bilibili.com/video/BV1GR4y1F7ko/?vd_source=fe55d765f380e65f0eb7ffde622fca56 这个是 NebulaGraph 的 up 主介绍悬挂边问题的视频,可以看下
好的
根据官网例子为什么查出来的player没有属性值呢
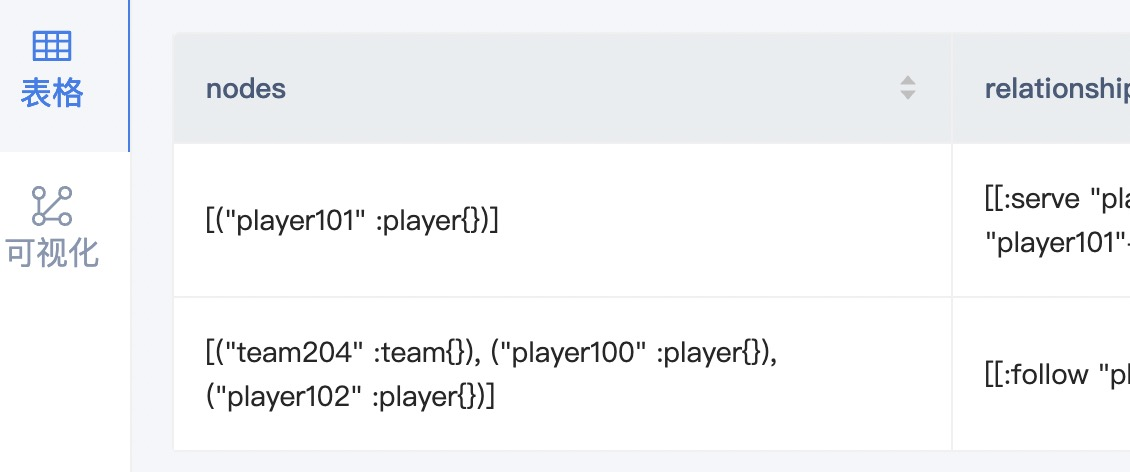
可视化里面可以看到,是指只有建立索引才会查出来属性值吗
我看文档上示例也是属性也是空的 https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/16.subgraph-and-path/1.get-subgraph/
子图/路径?
对的
with prop 带这个才会有属性,默认不带,代价不同
这句话没太理解,是指索引是等值比较等运算的必要条件吗
https://www.siwei.io/nebula-index-explained/ 关乎于查询起点是否知道 vid
请问MATCH语句如果想匹配tag1 or tag2该怎么写呢?MATCH (v:tag1:tag2)是tag1 & tag2的关系,想匹配v是tag1或tag2
match (v:PHONE) return v limit 3 UNION match (v:EMP) return v limit 3
Thx
请问现在有查询没有边关系的点的方法嘛
有,用 pattern expression
目前没有这种孤立点的pattern吧
有了,not (v)–(),把这个加在where条件那里
那没有指定的边关系的孤立点也可以用这个查询嘛
3.1.x以后match的where支持边条件了
好的好的
具体的语句可以参考这个:https://github.com/vesoft-inc/nebula/discussions/4316
谢谢大佬
[脸红]我看了一下这个是孤立点。
我的意思是,比如点是"水果",边分别是"进口"和"检疫",那么我想要查询没有检疫的进口水果,也可以用这个嘛
那要做个“进口”和“检疫”的差集?用MINUS嘛
get,谢谢
我也是今天早上头一次用MINUS
那问一下,where条件多的情况下,查询速度咋样哇
没试过大图,我理解应该就是两个查询分别的时间再加上一个求差的时间?后者应该不会有显著的耗时吧
各位大佬,求问一个,顶点一次SQL可以展开多层的关系数据么?
可以啊,这是基本能力
各位大佬问个问题:我在a标签插入了一个点vid为1,再在b标签插入一个点vid也为1,那么是不是vid为1这个点就属于两个不同标签了?
嗯嗯,顶点 “刘德华1960” 可以有演员和歌手两个tag
Q: go 语句中如果用到$$跟$^的话,哪个表示的是source,哪个表示的target
感谢
Q: 之前说的按边权重过滤子图的功能上线了吗
watch 这个 pr https://github.com/vesoft-inc/nebula/pull/4357
谢谢,我看下
Q: 大佬,我是想要get subgraph增加边过滤功能,这个和我想要的好像不太一样诶
这个就是实现这个的 pr,等它合并了就欧了
“match p=(v1)-->(v2) where id(v1) in [” + idlist + “] and id(v2) in [” + idlist + “] return p” , 试了一下这个语句 , and 没问题, or 就不行了
不能下推。加一个limit 也是报同样的错,哪位老师碰到过类似的情况么
建个索引吧,选不出来索引就会这样
是不还得定期的 rebuild index
一次建完,以后就不用了
我create database 的时候 创建的 index
你有tag index应该能选到啊
是 啊,and 可以,改成 or 就报那个不能下推
这个报错也很奇葩
我不记得是不是有个小版本修了这个问题
Q: 怎么设计graph的最大使用内存呢,电脑又炸了
这个目前的社区版设计不了
配置文件里边改个参数啥的来限制一下,这个应该可以吧
你可以用cgroup
Q: 集群和单机对内存的使用有区别吗
目前没区别 每个节点是独立的
Q: 节点独立是什么?就是说我现在一个查询请求过来,如果是单机的话,肯定就一台机器在处理这个请求了
但是如果是集群的话,会把这个请求拆分到不同节点来处理吗
目前版本在 graphd 这里不会拆
那集群是主要啥功能
集群可以服务更多查询,但单条查询目前没有做跨节点执行
意思是集群只会增加吞吐嘛
NebulaGraph 集群里面有 graphd,metad 和 storaged 三种节点,计算存储分离,数据分布在多个 storaged 节点里面,整体式 shared-nothing 架构,可以理解为是 weak scaling。增加 graphd 节点可以提高总吞吐上限,但可能不改变延迟;增加 storaged 有可能降低延迟,具体要配合其它操作了。目前没有做单挑查询的跨节点执行,这种执行可以理解为 strong scaling,这种方式是不一定能够降低延迟的。
噢噢 感谢科普 有了一些初步的印象
Q: 内存相关的问题,我们已经有多位同事在开发和优化了,不管是单条查询的内存用量(memory footprint),整个 graphd 对内存资源的占用(memory pool),还是对过量使用内存的查询的控制,在后续的版本里面我们都会做内核级别的设计和优化。感兴趣的朋友可以关注我们下个月的用户大会,以及后续发版。不过一般来讲处理偏分析型的查询,是需要比较大的内存的,不建议按照对传统 OLTP 数据库的资源预期来规划内存资源。
Q: 额外问一下,Nebula的提供图计算服务是要依赖Spark的是吧?
有依赖spark的graphx,也有不依赖的,不依赖的在企业版里
请问一下,复合语句是否支持match | delete VERTEX
不支持的呢
我现在的需求,需要查询所有孤点并删除,那该如何实现呢
结合管道符,删除符合条件的点。
nebula> GO FROM “player100” OVER serve WHERE properties(edge).start_year == “2021” YIELD dst(edge) AS id | DELETE VERTEX $-.id;
https://docs.nebula-graph.com.cn/3.2.1/3.ngql-guide/12.vertex-statements/4.delete-vertex/
Q: 你好,我现在是需要查询出没有边的点(孤点),然后再删除,go语法无法查找孤点吧
可以结合这个帖子先查询出孤点,再用 GO 语句删除?![]() :如何通过NGQL筛选出没有建立边关系的所有点、没建立指定边关系的所有点 - #10,来自 kyle
:如何通过NGQL筛选出没有建立边关系的所有点、没建立指定边关系的所有点 - #10,来自 kyle
Q: 请问,目前的Nebula studio,explorer是什么区别?除了开源商用外,底层是同样的技术实现么?
是的,studio可以当做是explorer子集,功能和代码层面都是